MACHINE LEARNING!!! So, if you’ve not heard of machine learning yet, you probably haven’t been watching any TV the last decade. Problem is machine learning is absolutely massive field.
This is the intro to a series of blog posts I plan on doing on various areas in machine learning, more specifically statistically backed methods therefore I call it statistical learning. In this blog post I aim to break down the two main areas that are generally focused on. I also give an applied example of each area.
So I have data set and I want to do some modelling of it. Statistical learning is basically a very large tool box, generally the first goal is to narrow down what tools you can use. To do this you have to ask a few questions to yourself. This is usually completely down to the structure of your data and what information is present. Here I’ll be focusing more on the what information is present side.
Supervised learning is focused on problems where you have the answer for some of your data. An example which you may already know of is linear regression, there’s a data set of potentially thousands of predictor variables \(x_i\) and then for each one of these points there’s a response variable \(y_i\). Data sets that have this response variable are called “labelled”. Methods which make use of this response variable are known as supervised methods. Generally want to find a model \(f(x)\) which will then do a pretty good job at predicting \(y\). Hence, the name supervised, we’re supervising our method by telling it that it wants to find \(y_i\).
On the other hand we have unsupervised learning, it’s where we have these \(x_i\) points but there’s no label with the data point. In the previous supervised case, most methods use the labels to estimate the function \(f(X)\). In unsupervised learning the methods must instead find their own function. Clustering is one of the most popular methods in this field, it involves splitting the data \(x\) into clusters.
Example - Supervised:
The iris data set is a classical data set used in statistics, it contains 4 features, sepal length, sepal width, petal length and petal width. Each observation has the species which it came from, therefore this data set is labelled so a supervised learning algorithm is ideal. This form of supervised learning is known as classification, this is when the label is a factor rather than a continuous number.
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 133 6.4 2.8 5.6 2.2 virginica
## 139 6.0 3.0 4.8 1.8 virginica
## 74 6.1 2.8 4.7 1.2 versicolor
## 71 5.9 3.2 4.8 1.8 versicolor
## 37 5.5 3.5 1.3 0.2 setosa
## 60 5.2 2.7 3.9 1.4 versicolor
## 75 6.4 2.9 4.3 1.3 versicolor
## 32 5.4 3.4 1.5 0.4 setosa
## 73 6.3 2.5 4.9 1.5 versicolor
## 7 4.6 3.4 1.4 0.3 setosaHere I’ll just use the features corresponding to sepal, this allows us to easily plot the data, however will probably result in a loss of accuracy. Here we’ll use the simplest supervised learning algorithm, k-nearest neighbours. You specify the number k, then the algorithm finds the k closest points, it then takes all of these as votes for the class label and the majority then is used as the prediction.
library(class)
set.seed(123)
#Subset the data
train <- iris[c(1,2)]
labels <- iris$Species
#fit the model
model <- knn.cv(train=train,cl=labels,k=5)
##Check % of correct
Error <- model!=labels
print(paste("Classification Error rate:",mean(Error)))## [1] "Classification Error rate: 0.226666666666667"##Plot
#iris
library(ggplot2)
iris_plot <- ggplot(aes(x=Sepal.Length, y=Sepal.Width, color=Species), data=iris)
iris_plot+geom_point(aes(shape=Error),size=4)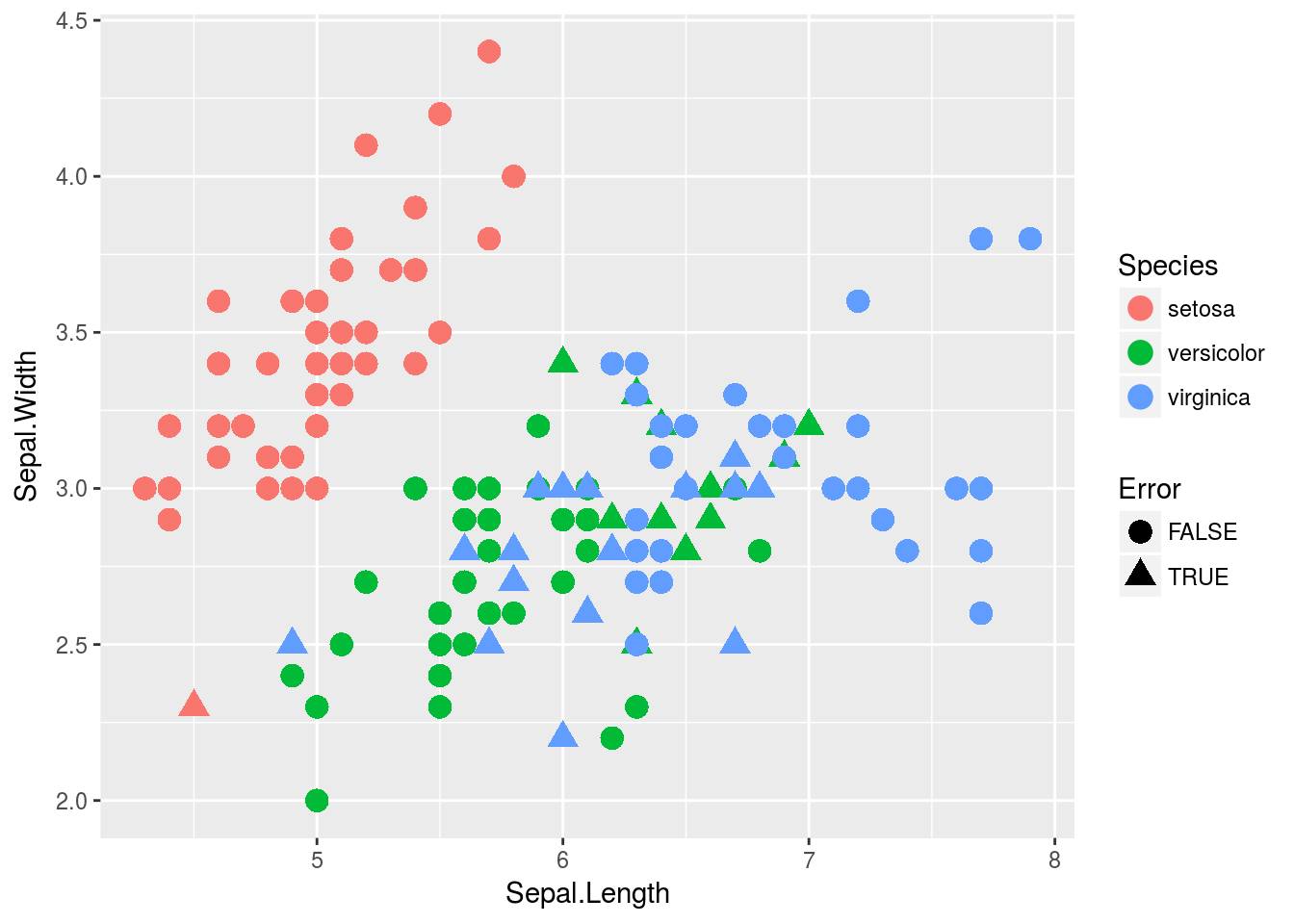
The classification error rate is a common measure of how many points were classified wrong. 0 being the best which means every point was classified correctly. I also plotted the in if our classifier correctly predicted the species, as you can see most of the errors tend to occur on the boundaries of the species or where there’s a data point in an unexpected place given its’ species.
Example - unsupervised
Here I give an example of clustering I’ll use geyser data set which includes measurements from the old faithful geyser. It involves 2 measurements,“eruptions” how long an Eruption lasted and “waiting” time until the next eruption.
faith_plot <- ggplot(aes(x=waiting,y=eruptions), data=faithful)+geom_point()
faith_plot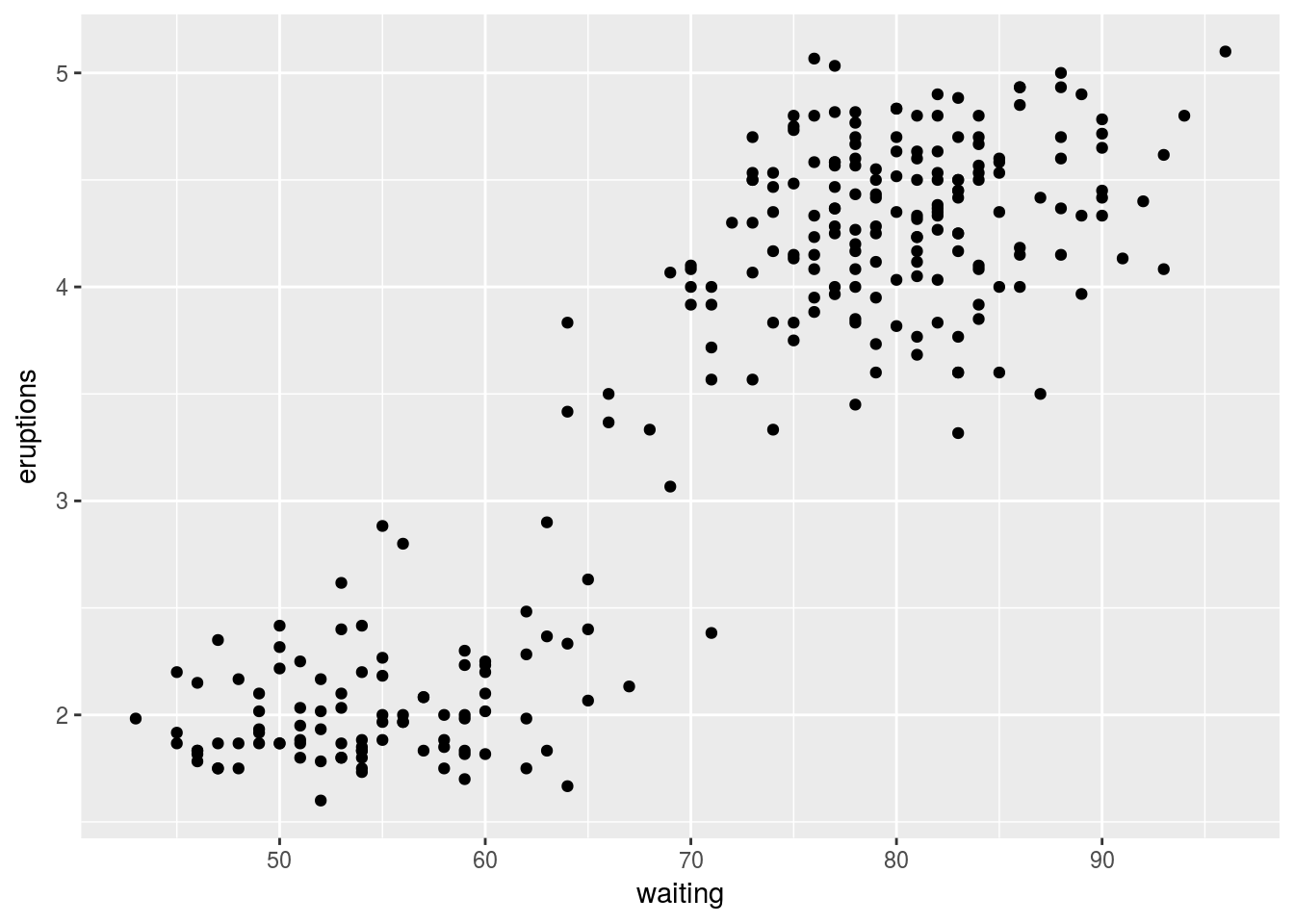
As we can see from the plot there’s 2 clear groups of data with a few random points in between Here I’ll use a similar method to before, it’s called k-means. For this method you specify k like before which is how many clusters the algorithm will choose, then it’ll find k centres. A point will be assigned to the closest centre. Looking at the picture it’s quite clear that k=2 is a good choice.
model <- kmeans(faithful,2)
Cluster_assignment <- as.factor(model$cluster)
ggplot(aes(x=waiting,y=eruptions,color=Cluster_assignment), data=faithful)+geom_point()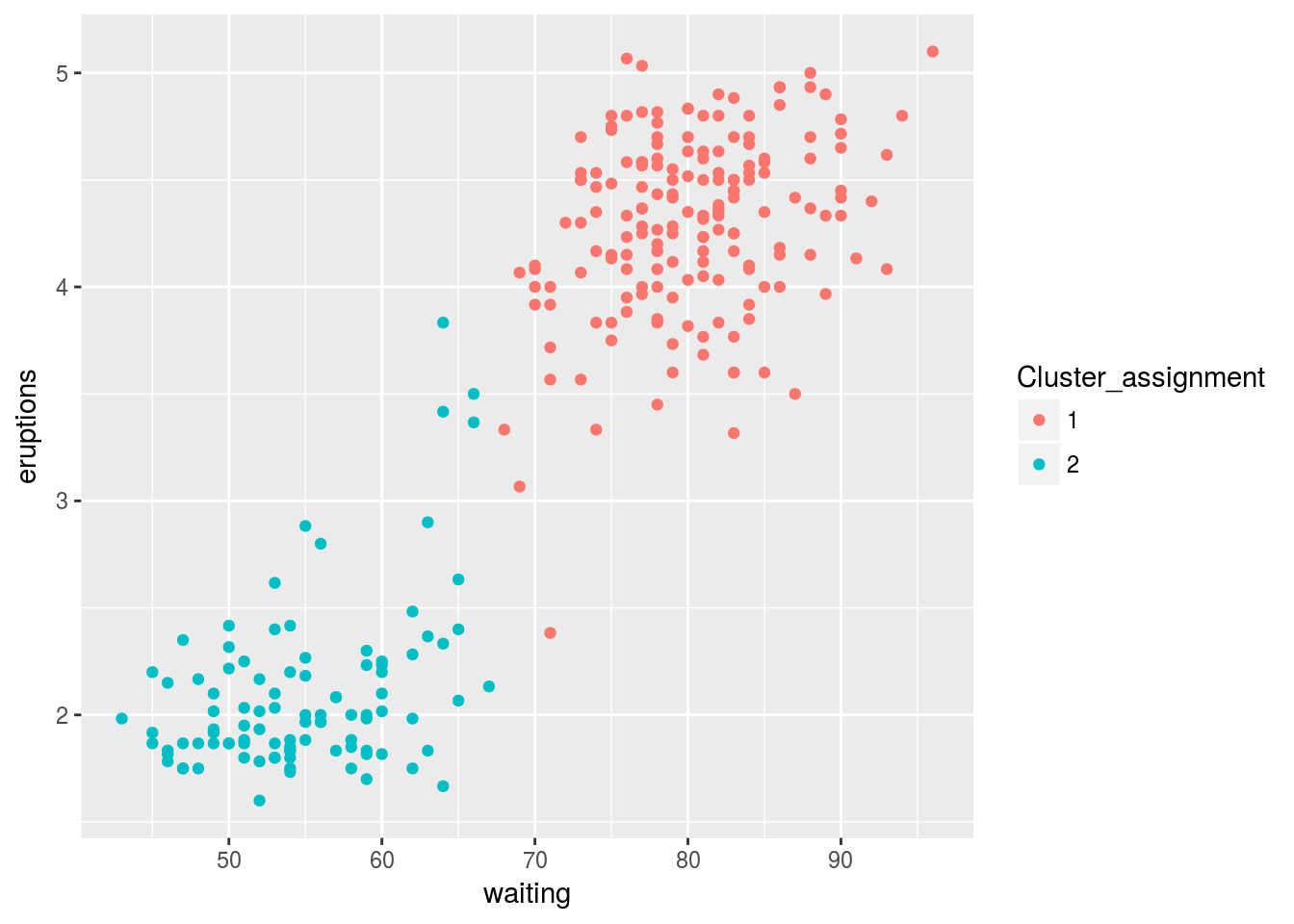 As you can see the k-means algorithm split the eruptions as we’d expect, one with high times and one with low times. This problem is quite trivial as there’s only two dimensions, it’s easy to see that a rule like “split if waiting time is over 70” would do just as well. When you get onto problems with more features it becomes much more difficult to separate clusters; therefore, more advanced analysis than just looking at a plot must be used.
As you can see the k-means algorithm split the eruptions as we’d expect, one with high times and one with low times. This problem is quite trivial as there’s only two dimensions, it’s easy to see that a rule like “split if waiting time is over 70” would do just as well. When you get onto problems with more features it becomes much more difficult to separate clusters; therefore, more advanced analysis than just looking at a plot must be used.
Summary
There’s a clear difficulty with unsupervised methods, you don’t know the answer. This makes it extremely difficult to say how good a solution is and often you’ll have two possible solutions which work equally well but you must choose one. Whereas, in supervised you can easily test how well the method does just by looking at the answer that’s in your data set i.e the classification error rate we used. There’s also hybrid method where the data is a mixture of labelled and non labelled points known as semi-supervised methods.
A good book that’s free which is basically a dictionary and guide book to using these methods can be found at An introduction to Statistical learning.